
执迷的博客 - Lovisnd BLOG
记录问题,学会成长
-
执迷的博客 - Lovisnd BLOG
记录问题,学会成长

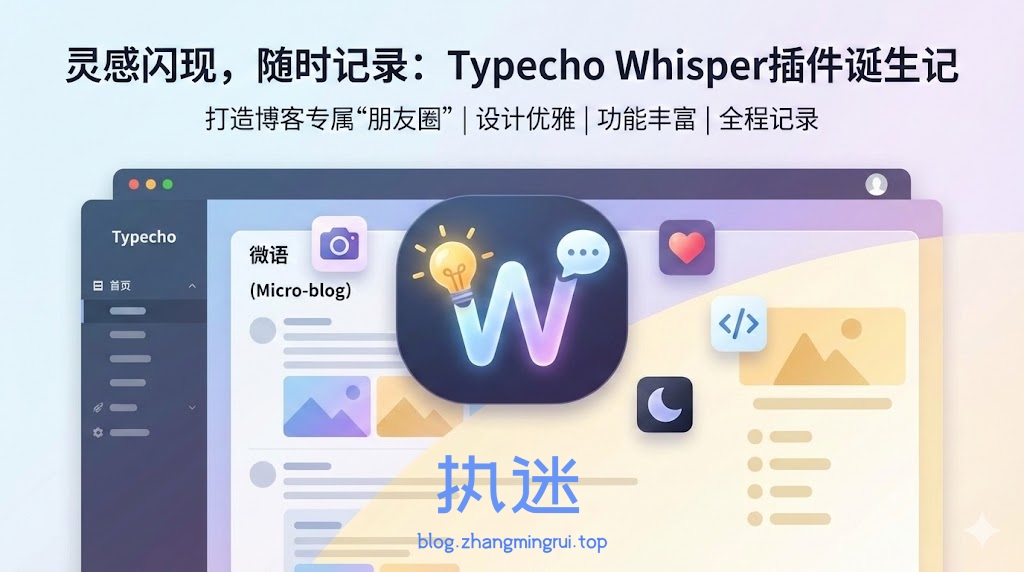
黄金大涨,我给媳妇手搓了一个“定制版”黄金管理APP
嫌黄金管理APP收费太贵?一位程序员老公霸气出手,为妻子定制专属免费版!他利用Python爬虫抓取金价,AI辅助设计界面,两天就搞定。这波操作不仅是技术实力的展现,更是教科书级的硬核浪漫。
执迷





执迷
日常记录开发中遇到的问题...
-
470359521 -
合肥 -
全栈工程师 -
Github - Lovisnd -
BY-NC-SA 4.0 -
皖ICP备2024056431号-1